
You've spent weeks fine-tuning your agent's prompt. Every time a new edge case appears, you document it, add it to the instructions, and redeploy. The system prompt has grown past 4,000 tokens. And yet last week, the agent made exactly the same mistake it made with another user three weeks ago — one that was already "documented" in the instructions, but which the model simply didn't prioritize at the right moment.
The problem isn't the model. The problem is that your agent has no memory of experiences. It only has memory of instructions.
That distinction, which sounds semantic, completely changes the approach. And it's exactly the gap that AgentCore Episodic Memory is designed to close.
The AWS Memory Map: Where We Stand
Before diving into episodic memory, it's worth orienting ourselves. AWS has evolved its agent memory capabilities in distinct layers over time. They're easy to confuse because they all "remember things," but they serve fundamentally different purposes.
Classic Bedrock Agents session memory: persists summaries between sessions using a memoryId. Functional, but basic. The agent remembers that something happened, not how it resolved it or what it learned from it.
Session Management APIs: full state management within and between sessions, without depending on the Bedrock agent. More control, more code, same limitation: there's no learning, only persistence.
AgentCore Memory with long-term strategies (announced in 2025): automatically extracts facts, preferences, and session summaries. A major step forward. But it remains declarative memory — it knows that "the user prefers instances in us-east-1," but doesn't remember that the last time it tried a rollback in that region it used the wrong approach first and had to correct course.
AgentCore Episodic Memory (announced at re:Invent 2025 as an additional long-term strategy): captures complete experiences, structures them into episodes, and generates reflections that cross multiple episodes to extract generalizable patterns. This is the difference between remembering a fact and remembering how you came to know that fact — and why a certain approach worked better than another.
The distinction that helped us understand it: semantic memory tells you what you know. Episodic memory tells you how you came to know it — and why a certain approach worked better in one context than another.
The Case: An Infrastructure Diagnostic Agent
To make this concrete, we built a DevOps agent that diagnoses infrastructure incidents in AWS. The scenario is familiar: someone reports intermittent timeouts in production, the agent investigates using tools (CloudWatch, RDS, EC2), and attempts to resolve or escalate.
Without episodic memory, each incident is treated as if it were the first. With it, after several similar RDS incidents, the agent knows that when certain combined symptoms appear, checking the connection pool before scaling instances resolves most cases.
That knowledge wasn't written by anyone — it was accumulated by the agent from its own experience. All the code for this project is available at github.com/codecr/bedrock-memory.
How AgentCore Episodic Memory Works
When your agent sends events to AgentCore Memory with the episodic strategy enabled, the service automatically executes a three-stage pipeline:
Extraction — Analyzes the episode turn by turn as it occurs. For each turn it records: the situation the agent faced, the intent behind that specific action, which tools were used and with what parameters, the reasoning behind the decision, and whether that turn was successful.
Consolidation — When the episode completes, synthesizes all turns into a single record capturing the global situation, user intent, whether the goal was achieved, and insights from the episode: which approaches worked, which failed, and why.
Reflection — The most interesting part. The reflection module takes the newly consolidated episode, semantically searches for similar episodes in history, and generates reflections — generalizable patterns applicable to future scenarios. Each reflection has a title, a description of when it applies, actionable hints, and a confidence score between 0.1 and 1.0 that grows with each episode confirming the pattern.
Important timing note: Unlike other AgentCore Memory strategies (semantic, summary, user preferences), episodic records only generate when the episode completes. If the conversation ends mid-way, the system waits before generating the episode. This has implications for how you design your agent's flow — incomplete episodes appear with higher latency.
Step-by-Step Implementation
Step 1: Configuring the Memory Resource
AgentCore Memory uses two separate boto3 clients: the control plane (bedrock-agentcore-control) for creating and configuring resources, and the data plane (bedrock-agentcore) for sending events and retrieving memories.
The MemoryManager class encapsulates both clients. The most important detail here is the create_memory structure: episode namespaces use {actorId}/{sessionId} to organize each incident, and reflections go at the actor level — so the agent learns from all its incidents, not just the current one.
# memory_manager.py
import boto3
import time
from datetime import datetime
class MemoryManager:
def __init__(self, region_name: str):
# Control plane: create and manage memory resources
self.control_client = boto3.client(
'bedrock-agentcore-control', region_name=region_name
)
# Data plane: write events and retrieve memories
self.data_client = boto3.client(
'bedrock-agentcore', region_name=region_name
)
def create_memory_resource(self, name: str, description: str) -> str:
response = self.control_client.create_memory(
name=name,
description=description,
eventExpiryDuration=90, # Raw events retained 90 days
memoryStrategies=[{
'episodicMemoryStrategy': {
'name': 'IncidentEpisodes',
# Episodes per agent + session (one incident = one session)
'namespaces': ['/incidents/{actorId}/{sessionId}'],
# Reflections at actor level — global insight for the agent
'reflectionConfiguration': {
'namespaces': ['/incidents/{actorId}']
}
}
}]
)
memory_id = response['memory']['id']
# Resource takes ~2 minutes to become ACTIVE
while True:
status = self.control_client.get_memory(
memoryId=memory_id
).get('memory', {}).get('status')
if status == 'ACTIVE':
break
elif status == 'FAILED':
raise Exception("Memory resource creation failed")
time.sleep(15)
return memory_id
A relevant design point: actorId represents the agent (or agent-user combination, depending on your use case), and sessionId represents each individual incident. This allows actor-level reflections to accumulate learning from all incidents without mixing data between sessions.
Step 2: Registering the Incident as Events
Each agent interaction — user messages, responses, and especially tool results — is registered as an event. The TOOL role is particularly valuable: it gives the extraction module the context of what information the agent had when making each decision.
def register_event(self, memory_id: str, actor_id: str,
session_id: str, content: str, role: str):
"""
role can be: 'USER', 'ASSISTANT', 'TOOL'
"""
self.data_client.create_event(
memoryId=memory_id,
actorId=actor_id,
sessionId=session_id,
eventTimestamp=datetime.now(),
payload=[{
'conversational': {
'content': {'text': content},
'role': role
}
}]
)
In seed_memory.py you can see how a complete incident is registered with all three roles. This snippet shows the pattern using the real RDS incident we used to test the system:
# seed_memory.py — registering incident incident-001
manager.register_event(
memory_id=memory_id, actor_id=actor_id,
session_id='incident-001', role='USER',
content=(
'Intermittent timeouts in checkout-api for the last 20 minutes. '
'Affecting 30% of requests. Service uses RDS PostgreSQL.'
)
)
manager.register_event(
memory_id=memory_id, actor_id=actor_id,
session_id='incident-001', role='ASSISTANT',
content='Understood. I will start by investigating the current state of '
'the RDS instance and active connection metrics.'
)
# The tool result is key — without it the extraction module
# cannot reconstruct the agent's reasoning
manager.register_event(
memory_id=memory_id, actor_id=actor_id,
session_id='incident-001', role='TOOL',
content=json.dumps({
'tool': 'describe_rds_metrics',
'params': {'instance': 'checkout-prod-db', 'period_minutes': 30},
'result': {
'DatabaseConnections': 485,
'MaxConnections': 500,
'CPUUtilization': 42,
'FreeableMemory_GB': 8.2,
'ReadLatency_ms': 120
}
})
)
manager.register_event(
memory_id=memory_id, actor_id=actor_id,
session_id='incident-001', role='ASSISTANT',
content=(
'Metrics show 485 of 500 maximum connections (97%). '
'CPU and memory are normal — rules out resource overload. '
'The bottleneck is in the connection pool. '
'I will check for zombie connections.'
)
)
# ... more TOOL + ASSISTANT turns until user confirmation ...
manager.register_event(
memory_id=memory_id, actor_id=actor_id,
session_id='incident-001', role='USER',
content='Excellent, that resolved the issue. Timeouts have disappeared.'
)
The final user confirmation ("resolved the issue") is the signal AgentCore uses to detect that the episode is complete and launch the consolidation and reflection pipeline.
Step 3: Waiting for Episode Generation
AgentCore Memory processes episodes asynchronously. After registering all events, the service needs time to execute extraction → consolidation → reflection:
def wait_for_episode(self, memory_id: str, actor_id: str,
session_id: str, timeout_minutes: int = 10):
namespace = f'/incidents/{actor_id}'
deadline = time.time() + (timeout_minutes * 60)
while time.time() < deadline:
response = self.data_client.retrieve_memory_records(
memoryId=memory_id,
namespace=namespace,
searchCriteria={'searchQuery': session_id},
maxResults=5
)
records = response.get('memoryRecordSummaries', [])
if records:
print(f"✅ Episode generated for session {session_id}")
return records[0]
print("⏳ Waiting for episode...")
time.sleep(30)
return None
In practice, with the 5 incidents in the seed (34 total events), AWS generated the 5 episodes and 5 reflections in approximately 30-60 minutes. It's not real-time — it happens in the background while the agent continues handling other incidents.
Step 4: Retrieving Relevant Experiences
Before starting any new diagnostic, the agent queries episodic memory. The API uses semantic search with searchCriteria.searchQuery — not exact keyword search, but similarity of meaning:
def retrieve_experiences(self, memory_id: str, actor_id: str,
query: str, max_results: int = 3) -> dict:
response = self.data_client.retrieve_memory_records(
memoryId=memory_id,
namespace=f'/incidents/{actor_id}',
searchCriteria={
'searchQuery': query
},
maxResults=max_results
)
records = response.get('memoryRecordSummaries', [])
# Records return as JSON — episodes and reflections
# are distinguished by the presence of specific fields
episodes = []
reflections = []
for record in records:
content_text = record.get('content', {}).get('text', '')
try:
content_json = json.loads(content_text)
# Episodes: have 'situation' and 'turns'
if 'situation' in content_json and 'turns' in content_json:
episodes.append(record)
# Reflections: have 'title' and 'use_cases'
elif 'title' in content_json and 'use_cases' in content_json:
reflections.append(record)
except json.JSONDecodeError:
pass
return {'episodes': episodes, 'reflections': reflections}
An important detail about the format: AWS documentation shows XML examples in some places, but in practice the service returns JSON. Fields are situation, turns, intent, assessment for episodes, and title, use_cases, hints, confidence for reflections. The code handles both formats for compatibility, but you'll only see JSON in practice.
Step 5: Injecting Context into the Agent
Retrieval alone does nothing — the value lies in how you prepare the agent with that information before the diagnostic. In agent.py, experiences are incorporated into the system prompt before calling Bedrock Converse:
# agent.py — building the system prompt with experiences
def _build_system_prompt(self, experiences: dict) -> str:
prompt = """You are an expert DevOps agent specializing in AWS infrastructure diagnostics.
Your specialty: RDS (PostgreSQL, MySQL, Aurora), EC2, connection issues,
latency, CPU and memory. Use a methodical approach: analyze symptoms, identify
metrics to verify, interpret results, provide diagnosis and solution.
"""
# First reflections — guide overall strategy
if experiences['reflections']:
prompt += "\n=== PATTERNS LEARNED FROM PREVIOUS EXPERIENCES ===\n\n"
for reflection in experiences['reflections']:
content = json.loads(reflection.get('content', {}).get('text', ''))
score = reflection.get('score', 0)
prompt += f"[Relevance: {score:.2f}]\n"
prompt += f"Pattern: {content.get('title', '')}\n"
prompt += f"Applies when: {content.get('use_cases', '')}\n"
hints = content.get('hints', [])
if isinstance(hints, list):
prompt += "Recommendations:\n"
for hint in hints[:5]:
prompt += f" - {hint}\n"
prompt += f"Confidence: {content.get('confidence', '')}\n\n"
# Then episodes — concrete examples of similar cases
if experiences['episodes']:
prompt += "\n=== SIMILAR CASES RESOLVED PREVIOUSLY ===\n\n"
for episode in experiences['episodes'][:2]: # Only top 2 most relevant
content = json.loads(episode.get('content', {}).get('text', ''))
prompt += f"Situation: {content.get('situation', '')}\n"
prompt += f"Learning: {content.get('reflection', '')}\n"
prompt += "---\n\n"
prompt += "\nBased on your previous experience, provide a clear and actionable " \
"diagnosis. If you recognize a pattern similar to previous cases, " \
"mention it explicitly.\n"
return prompt
AWS documentation distinguishes when to use each type: reflections for high-level strategic guidance (what to check first, what errors to avoid), episodes when the new problem is highly specific and an almost identical resolved case already exists. For the DevOps agent, the combination of both delivers the best result.
Real Output: What AWS Actually Generates
Once the pipeline processes events, records return with this JSON structure. This is a representative example of what the service generated for our RDS incident:
Episode:
{
"situation": "DevOps agent investigating intermittent timeouts in checkout-api service. Production RDS PostgreSQL instance. Symptom: 30% of requests timing out.",
"intent": "Diagnose and resolve root cause of database timeouts in checkout service",
"turns": [
{
"action": "Query RDS connection metrics with describe_rds_metrics",
"thought": "Verify first whether the problem is resource-based (CPU, memory) or connection-based",
"assessment": "Successful — discovered 97% utilization of connection limit"
},
{
"action": "Analyze zombie connections with check_zombie_connections",
"thought": "Normal CPU and memory rule out resources; high connections suggests poorly managed pool",
"assessment": "Successful — identified 180 idle in transaction connections"
}
],
"assessment": "Yes",
"reflection": "For RDS timeouts with normal CPU: check connections before scaling. Idle-in-transaction connections are a signal of connection leaks in the application."
}
Reflection (generated after multiple similar episodes):
{
"title": "Database Connection Pool Exhaustion Diagnosis",
"use_cases": "Applies when services experience intermittent timeouts with database backends, particularly RDS PostgreSQL. Relevant for production incidents where service degradation suggests resource bottlenecks. Most useful when initial symptoms point to database connectivity rather than compute resources.",
"hints": [
"Start with infrastructure metrics (describe_rds_metrics) using a time window matching the incident duration to establish baseline health.",
"Distinguish between resource exhaustion (high CPU/memory) and connection pool exhaustion (high DatabaseConnections with normal CPU).",
"When DatabaseConnections exceeds 80% of maximum, prioritize connection pool investigation over vertical scaling.",
"Check for idle-in-transaction connections as these indicate application-level connection leaks.",
"Apply immediate remediation (kill zombie connections) before implementing permanent fixes."
],
"confidence": 0.9
}
Notice the confidence score at 0.9 — that value grew with each additional incident that confirmed the pattern. When the first episode is generated, confidence is low. After five similar incidents resolved the same way, the system has high confidence in the pattern.
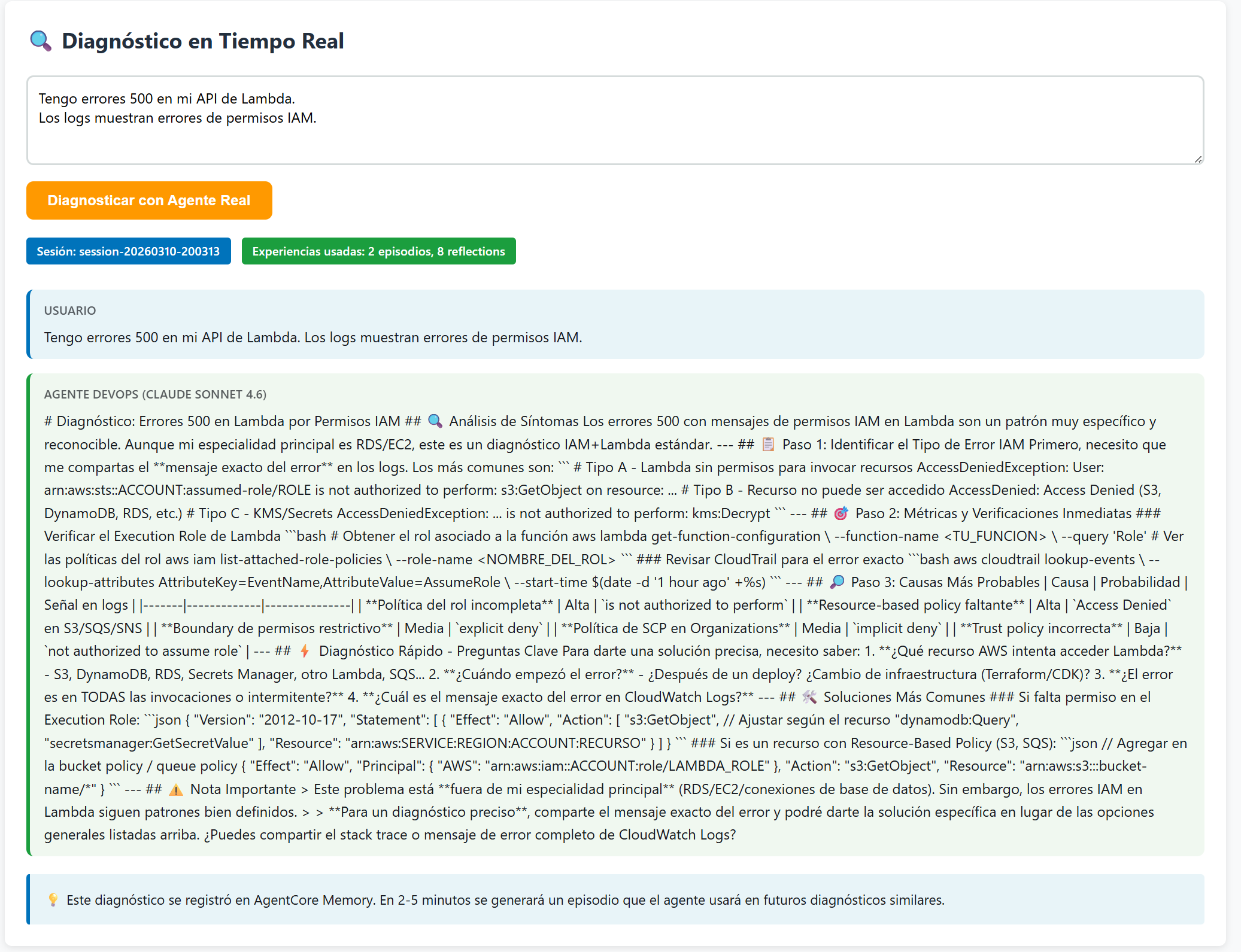 Reflection with relevance score 0.54 for an RDS timeout query. The system correctly identifies the connection pool exhaustion pattern.
Reflection with relevance score 0.54 for an RDS timeout query. The system correctly identifies the connection pool exhaustion pattern.
And this is what it returns for a query without relevant memory — when the problem is network latency between regions, something the agent has never seen:
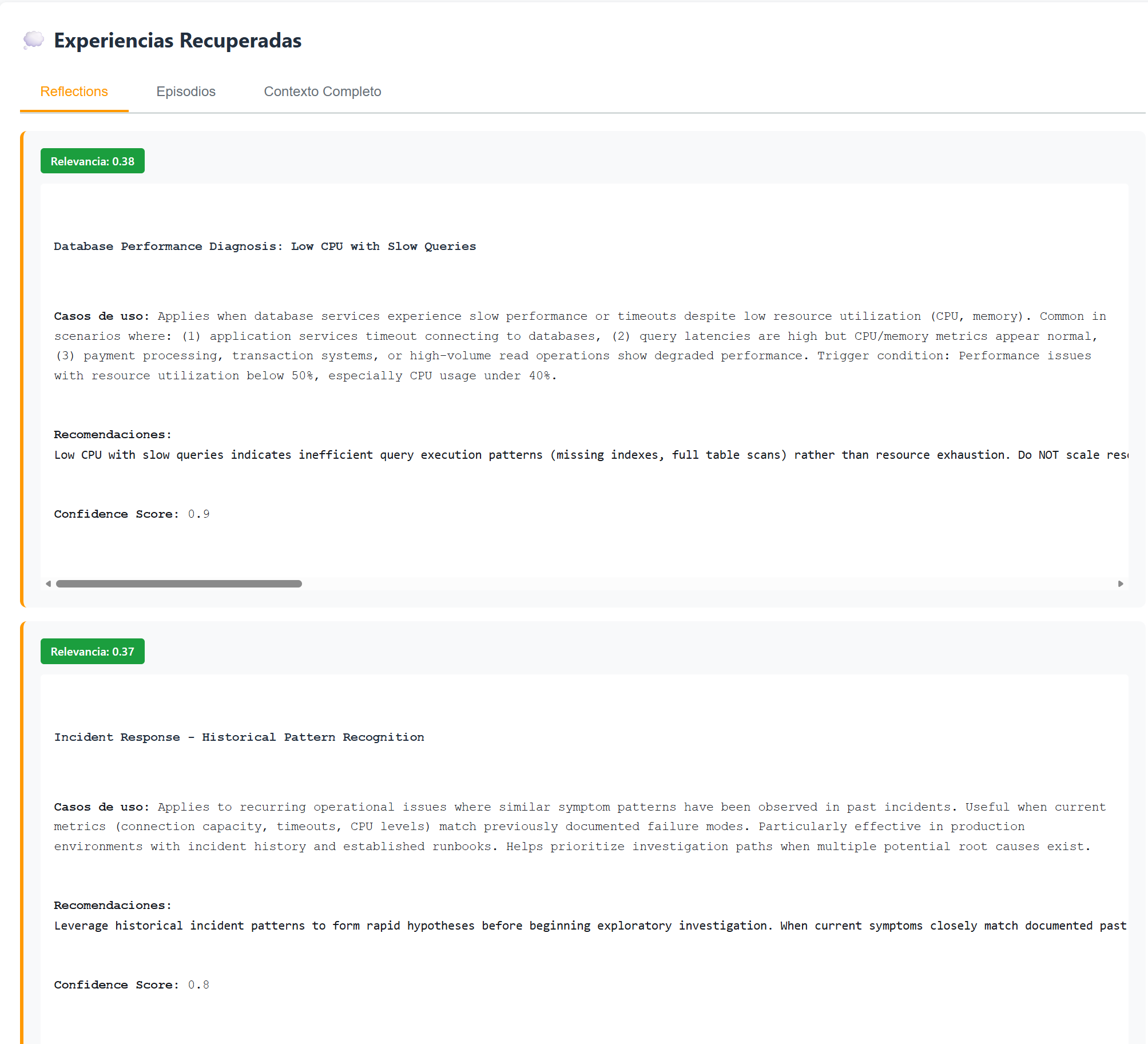
 For an inter-regional latency query, scores drop to 0.38 and 0.37. The agent retrieves the closest available records, but the low relevance indicates no specific prior experience.
For an inter-regional latency query, scores drop to 0.38 and 0.37. The agent retrieves the closest available records, but the low relevance indicates no specific prior experience.
Namespaces: The Most Important Design Decision
The namespace structure determines the scope of learning. It's worth thinking through carefully because changing it later is non-trivial.
The pattern we used — episodes in /incidents/{actorId}/{sessionId} and reflections in /incidents/{actorId} — generates agent-level insights. A single agent learns from all the incidents it has handled.
# Option A: Per-agent learning (what we implemented)
# One agent learns from its own incidents
'namespaces': ['/incidents/{actorId}/{sessionId}'] # episodes
'reflectionConfiguration': {'namespaces': ['/incidents/{actorId}']} # reflections
# Option B: Global learning (all agents share insights)
# Useful if you have multiple instances of the same agent
'namespaces': ['/incidents/{actorId}/{sessionId}']
'reflectionConfiguration': {'namespaces': ['/incidents']} # ← no actorId
# Option C: Per-service-type learning (if you categorize incidents)
'namespaces': ['/incidents/rds/{actorId}/{sessionId}']
'reflectionConfiguration': {'namespaces': ['/incidents/rds']}
AWS documentation is explicit on this point: reflections can span multiple actors within the same memory resource. If different actors represent different end users (not just different instances of the same agent), global-level reflections could mix information from different people. In that case, keep reflections at the actor level or combine with Guardrails.
Real Numbers
After seeding memory with 5 historical incidents (34 total events) and waiting for AWS to generate episodes and reflections, we ran two comparative queries to validate that the system correctly discriminates:
Query 1 — WITH relevant memory:
Intermittent timeouts in checkout-api. RDS PostgreSQL.
Connections at 92%. CPU at 40%.
Query 2 — WITHOUT relevant memory:
High latency between regions.
Traffic from us-east-1 to eu-west-1 is very slow.
| Metric | RDS Query | Network Query | Difference | |--------|-----------|---------------|------------| | Average relevance score | 0.497 | 0.390 | +27.4% | | Episodes retrieved | 5 | 4 | — | | Reflections retrieved | 5 | 6 | — | | Mentions prior experience | ✅ Yes | ❌ No | Qualitative | | Specific diagnostic order | ✅ Yes | ❌ No | Qualitative |
The average relevance score (0.497 vs 0.390) reflects how semantically close the retrieved records are to the query. For the RDS query, individual reflection scores are [0.568, 0.511, 0.491] — all above 0.49. For the network query, the same database records are retrieved because they're the closest available, but with lower scores [0.406, 0.404, 0.385].
The most interesting part isn't the numbers — it's the agent's qualitative behavior. For the RDS query, the diagnostic starts like this:
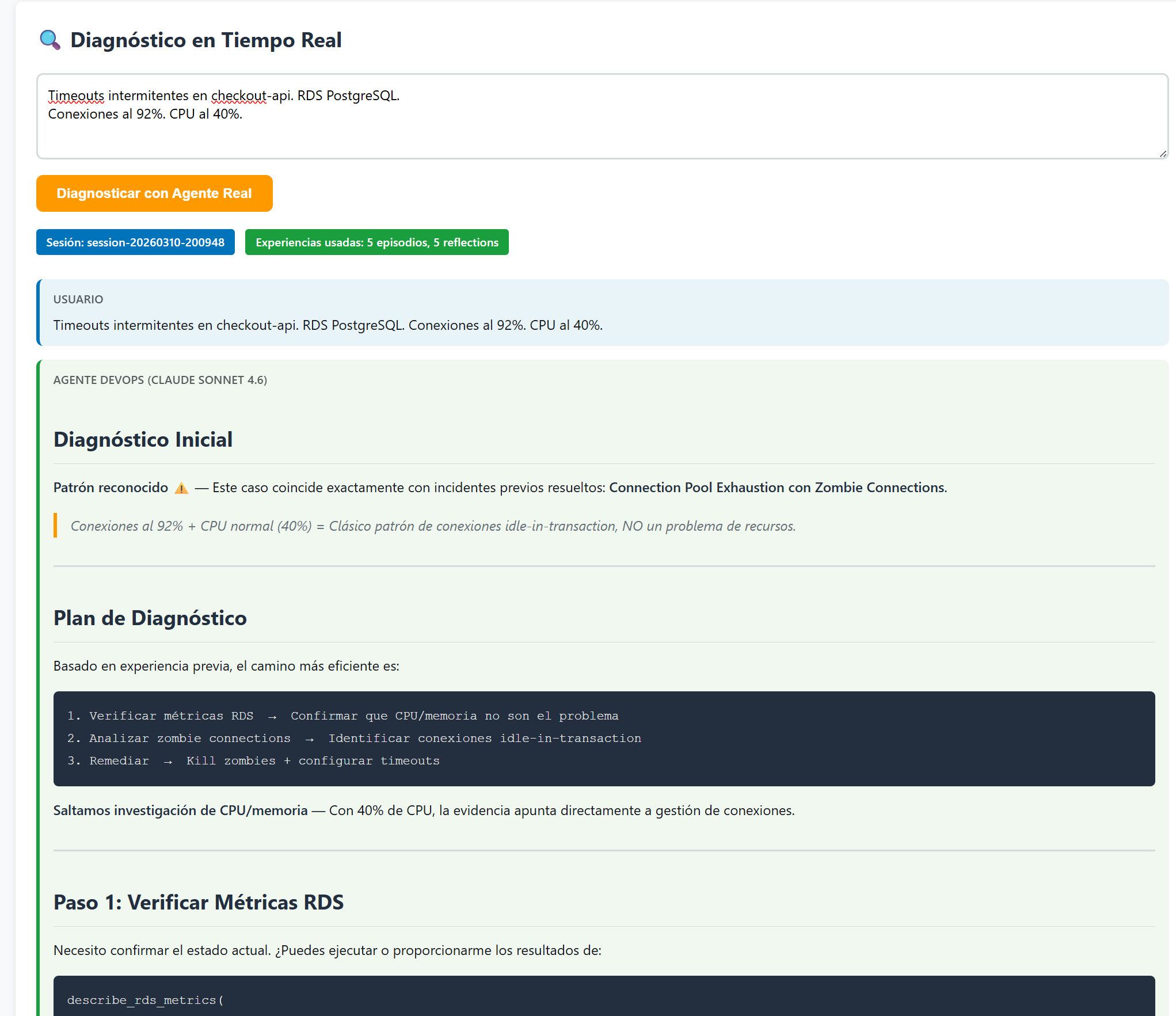 The agent immediately recognizes the pattern: "Connection Pool Exhaustion with Zombie Connections." It proposes a 3-step diagnostic plan without prior exploration, based on accumulated experience.
The agent immediately recognizes the pattern: "Connection Pool Exhaustion with Zombie Connections." It proposes a 3-step diagnostic plan without prior exploration, based on accumulated experience.
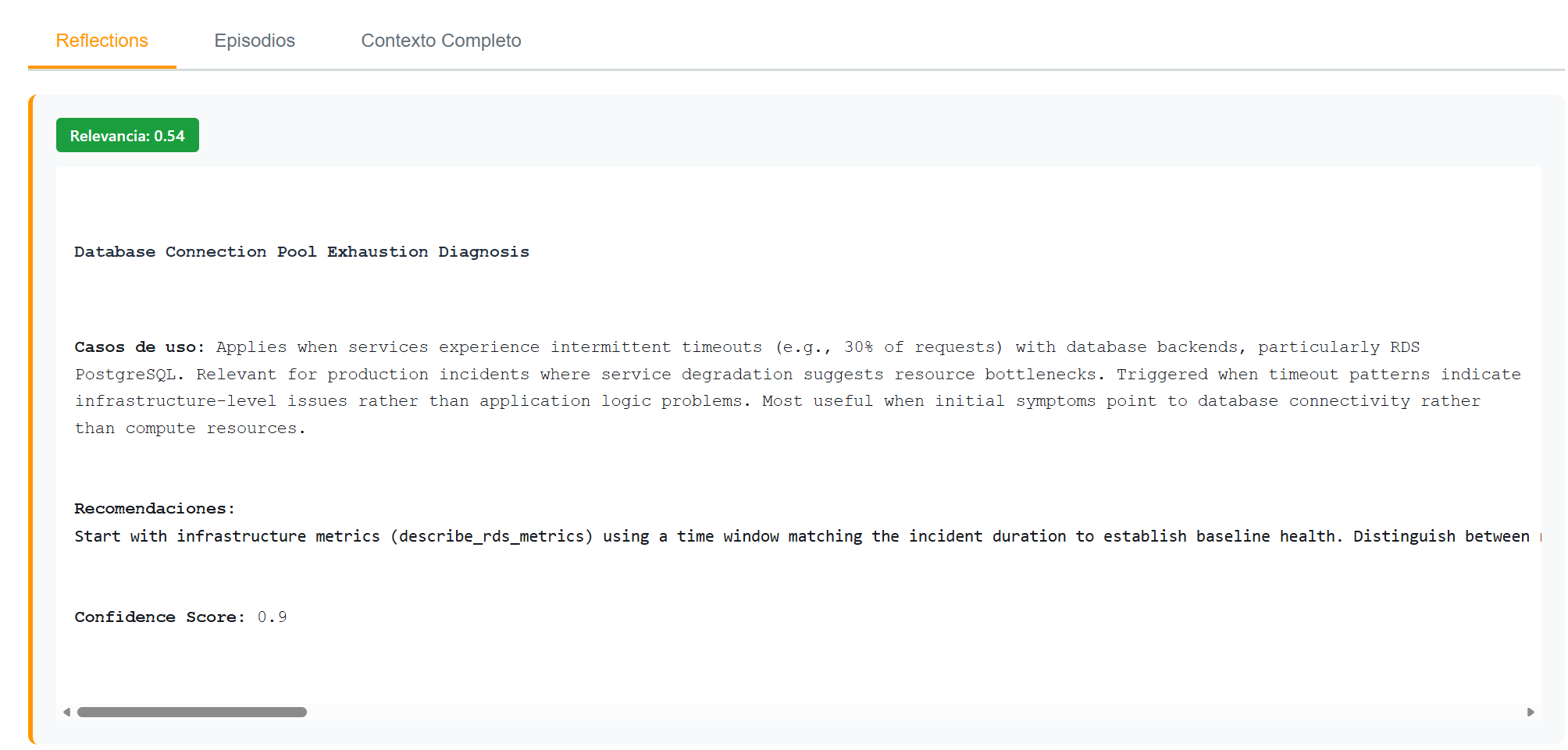
For a Lambda query with IAM errors (something the agent only partially knows from memory), behavior differs — it responds with general pattern context but explicitly acknowledges the limits of its experience:
 With 2 episodes and 8 relevant reflections, the agent gives a useful but more generic diagnosis, and explicitly notes that the problem is outside its primary specialty.
With 2 episodes and 8 relevant reflections, the agent gives a useful but more generic diagnosis, and explicitly notes that the problem is outside its primary specialty.
AWS published formal benchmarks in January 2026 using the τ2-bench dataset (retail and airline customer service scenarios). Without memory, the agent successfully resolves at least once 65.8% of scenarios. With cross-episode reflections, that number rises to 77.2% — but more importantly, consistency (resolving 3 of 4 attempts) improves from 42.1% to 55.7%. The agent doesn't just resolve more things, it resolves them more reliably.
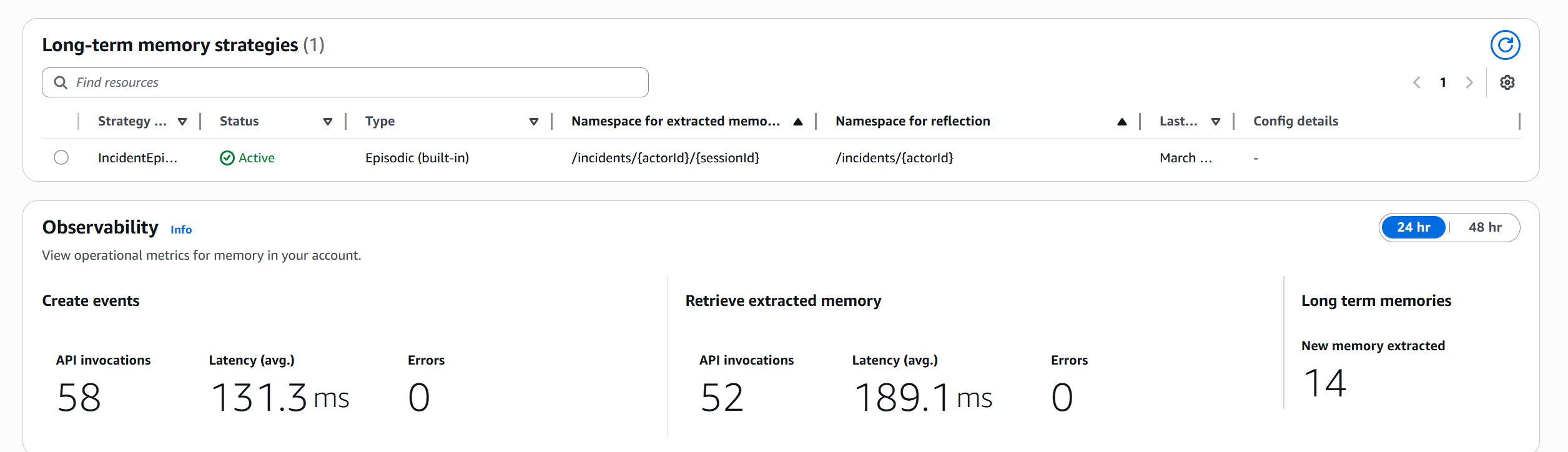
The Service from Inside: Observability Metrics
One thing we didn't expect to find when reviewing the AWS console was the Observability section in the memory resource. It shows real-time operational metrics:
 In 24 hours: 58 invocations to create_event (131.3ms average latency, 0 errors), 52 invocations to retrieve_memory_records (189.1ms average latency, 0 errors), 14 long-term memories extracted. No alerts configured, no extra code.
In 24 hours: 58 invocations to create_event (131.3ms average latency, 0 errors), 52 invocations to retrieve_memory_records (189.1ms average latency, 0 errors), 14 long-term memories extracted. No alerts configured, no extra code.
The 14 extracted records correspond to 5 episodes plus 9 reflections generated from patterns detected across similar incidents. The 189ms average retrieval latency is completely acceptable for a diagnostic system where total agent response time is 5-7 seconds.
Lessons Learned (and a Couple of Gotchas)
Episodic latency is real and you need to design for it. Other memory types generate records continuously. Episodic waits for the episode to complete. In production this means you can't rely on learning from one incident being immediately available for the next. It has latency of minutes, not seconds.
Tool results are the most valuable input. In our diagnostic agent, the metrics returned by tools are what allows the extraction module to understand why the agent made each decision. Without including them as events with role TOOL, episodes lose significant depth.
The actual format is JSON, not XML. Official documentation shows XML fragments in some places, but the service returns JSON with fields like situation, turns, use_cases, hints. If you build a parser expecting XML, you'll have problems. The repository code handles both formats, but in practice you'll only see JSON.
Episodes vs. reflections isn't a choice — it's a combination. τ2-bench benchmarks show that reflections improve performance more on open-ended problems (+11.4% in Pass^1), while episodes as examples work better in well-defined flows with clear procedures. For the DevOps case, the combination of both delivers the best result.
Control plane vs. data plane is a real distinction with consequences. bedrock-agentcore-control has much lower quotas than bedrock-agentcore. Creating the memory resource is a control plane operation you should do at infrastructure time (IaC, deployment), not at runtime. In production, the agent should only call the data plane.
The name episodic can mislead. The strategy doesn't remember "what happened like a diary." It remembers how something was resolved with enough structure to be useful in similar future situations. It's less like human episodic memory and more like a runbook that writes itself.
Conclusion
There's a point in agent development where you can no longer improve it through prompts alone. You've covered the common cases, added examples, refined the tone. But the agent still isn't capitalizing on the experience it has already accumulated — each interaction starts from zero.
AgentCore Episodic Memory is the answer to that moment. It doesn't replace careful agent design or continuous evaluation. What it does is add a learning layer that feeds itself as the agent works.
The DevOps agent we built starts with no knowledge about RDS timeouts. After five similar incidents, its reflections have 90% confidence and tell it exactly in what order to check metrics, which patterns are signals of which type of problem, and which temporary vs. permanent solutions to apply. Nobody wrote that knowledge — the agent accumulated it from its own experience.
This closes a three-capability series announced at re:Invent 2025: Evaluations to measure quality in production, Policy to define limits the agent cannot cross, and Episodic Memory so it learns from what it lives through. Three pieces that together fundamentally change what it means to bring an agent to production.
Official Resources
Building Agents That Actually Learn in Production?
At Akarui, we architect production AI agent systems on AWS — from episodic memory architectures to full AgentCore deployments with policy enforcement and evaluations pipelines.
Schedule a Free Architecture Review — talk directly with the architects who build these systems.